AWK в Linux. Язык обработки текстовых данных на примерах.
09 Jun 2026, 20:08:04
Основная работа с любыми Linux и Unix системами происходит посредством управления текстовыми потоками. Команды, конфигурационные файлы, логи, вывод и ввод данных - всё это текст, которым мы должны управлять.Для эффективного управления текстовыми данными в 1977 году был создан специализированный язык программирования AWK. Название происходит от первых букв фамилий авторов: Альфред Aхо, Питер Wайнбергер и Брайан Kерниган.
Спустя много десятилетий AWK остаётся одним из базовых инструментов для работы в Linux и Unix системах и входит в стандартный набор ПО многих дистрибутивов на их базе.
В этой статье мы рассмотрим синтаксис, базовые параметры, конкретные примеры применения популярного языка.
Принцип работы AWK
Быстродействие утилиты AWK обусловлено её умением читать входящий поток или файл построчно, независимо от размера входного потока данных. Модель работы программы основывается именно на этом:- Чтение строки;
- Разделение строки на поля;
- Проверка условия;
- Выполнение действий;
- Переход к следующей строке.
Структура скрипта AWK
Полная структура скрипта AWK состоит из трёх блоков:BEGIN { }Выполняется перед чтением данных./search_pattern/Шаблон поиска.{ print $1 }Основной блок инструкций, которые применяются к каждой записи.END {
print "Done"
}Выполняется после обработки всех данных.Однако в повседневных задачах AWK обычно используется для быстрой обработки данных одной строкой, поэтому блоки BEGIN и END почти никогда не встречаются. Более привычен упрощённый вид команды. Например:
awk -F ':' '{ print $1 }' /etc/passwd- -F - задаёт разделитель (по умолчанию пробел и табуляция).

В данном примере мы использовали переменную $1, в которую AWK помещает первое поле строки. Указали разделитель ":", так как именно он используется в исходном файле.
AWK создаёт столько переменных, сколько полей найдено в строке. Нумерация начинается с единицы ($1). Переменная $0 содержит всю строку целиком.
Помимо классических переменных, существуют специальные переменные AWK, которые хранят информацию об исходных данных.
Специальные переменные AWK
| Переменная | Назначение |
| NR | Номер текущей записи |
| NF | Количество полей |
| FNR | Номер строки в текущем файле |
| FS | Разделитель полей |
| RS | Разделитель записей |
| OFS | Разделитель выходных данных |
| ORS | Разделитель строк выходных данных |
awk -F ':' -v OFS='|' '{ print NR,$1,$6 }' /etc/passwd- -F - задаёт разделитель;
- -v - присваивает значение переменной;
- NR - номер текущей строки;
- $1 и $6 - первое и шестое поле.

Мы также можем формировать строку самостоятельно:
awk -F ':' -v OFS='' '{ print NR,". ",$1,": ",$6 }' /etc/passwdОбратите внимание на то, что мы изменили переменную OFS='' присвоив ей пустую строку в качестве разделителя, чтобы получить нужный нам формат вывода.
Примеры использования AWK
Как и многие другие языки программирования, AWK умеет работать с массивами. На практике это можно применить, например, для вывода топа IP адресов по количеству запросов из лога nginx:awk '{ ip[$1]++ } END { for(k in ip) print ip[k], k }' access.log | sort -nr | headВ этом сценарии мы создаём ассоциативный массив ip, куда добавляем элементы, где ключ - это IP адрес, а значение - количество строк, в первом поле которых этот IP встречался. Далее с помощью цикла выводим все элементы массива и их значение.
AWK может посчитать и количество уникальных пользователей (уникальных IP-адресов в логе nginx сайта):
awk '{ ip[$1]=1 } END { print length(ip) }' access.logВ этом выражении мы задействовали встроенную функцию AWK length(), которая выводит количество элементов массива ip. Конечно же это грубый пример, который учитывает все запросы к сайту, в том числе и различных ботов.
С помощью AWK возможно проверять условия. Выведем из лога Nginx все запросы, которые получили код ошибки:
awk '$9 >= 400 { print $0 }' access.logМы проверяем значение девятого поля ($9) и сравниваем его с числом 400 (коды ответа равные 400 и больше означают ту или иную ошибку), если значение больше или равно - выводим всю строку.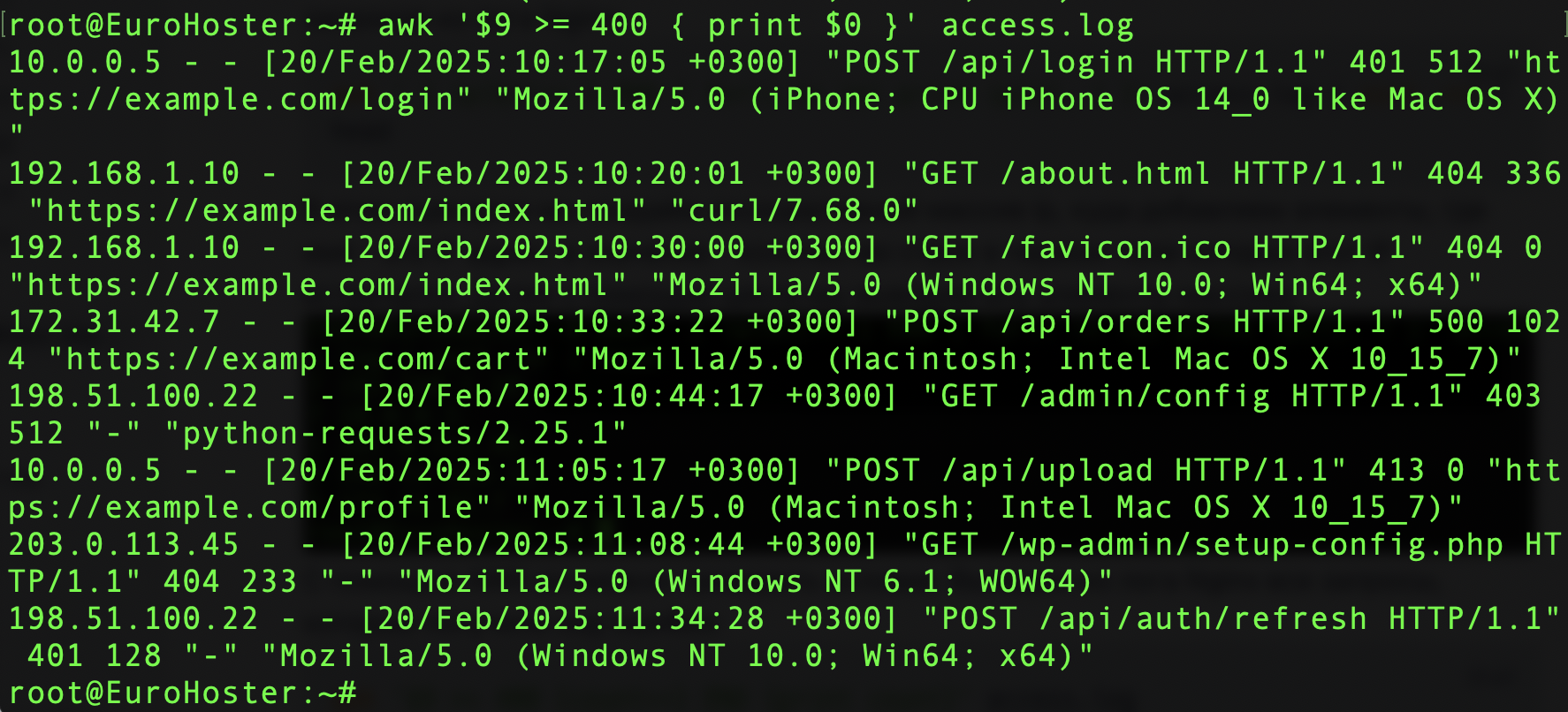
Или найдём все успешные запросы (код 200) к URI /api:
awk '$7 ~ /^\/api/ && $9 == 200 {print $0}' access.logМы проверяем значение седьмого поля на соответствие регулярному выражению и девятое на равенство. Наглядно демонстрируем, что AWK поддерживает логические операторы: || (логическое ИЛИ), && (логическое И), ! (отрицание)).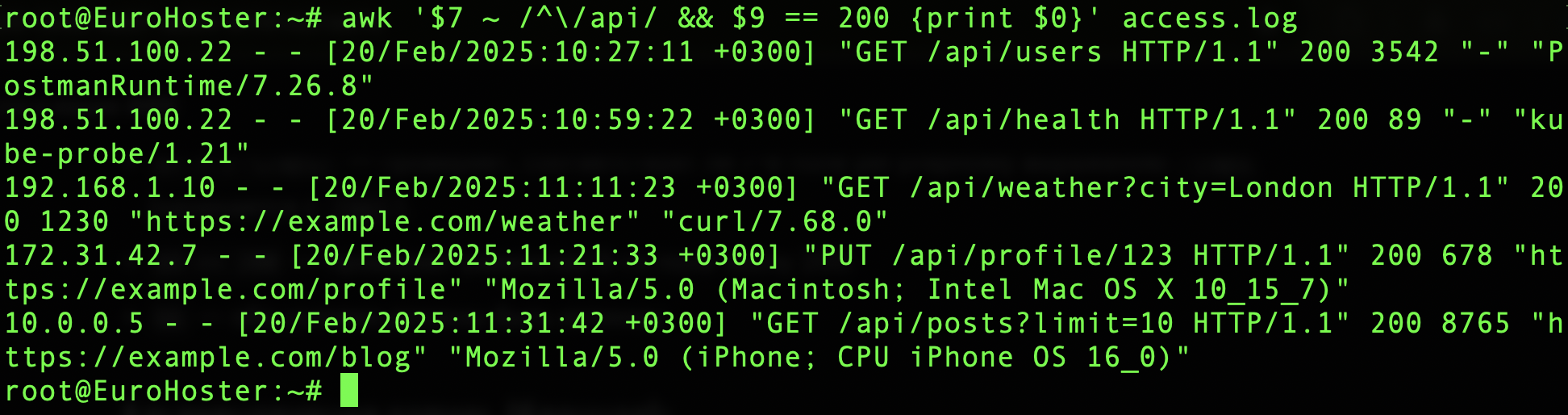
Полезный пример: найдём самые посещаемые URL из лога nginx:
awk '{ url[$7]++ } END { for(u in url) print url[u], u }' access.log | sort -nr | headВ основном блоке скрипта AWK создаёт и заполняет массив url значением седьмого поля($7). После выполнения основного блока, утилита выводит количество обращений и сам URL с помощью цикла for. Команда sort -nr сортирует исходные данные как числа и меняет порядок сортировки. head выводит первые 10 строк.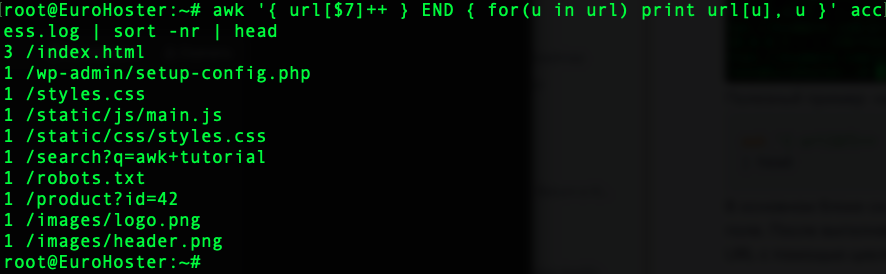
Есть и более интересные, но простые примеры. Найдём процессы, потребляющие более 50% CPU:
ps aux | awk '$3 > 50'
Или найдём процессы, потребляющие более 500 МБ ОЗУ:
ps aux | awk '$6 > 500000 {print $2, $11, $6}'Формируем вывод самостоятельно, выводя только 2-е, 11-е и 6-е поля, сравнивая 6-е поле.
Продолжая тему математики, мы также можем посчитать среднее значение по столбцу. Например имеем файл users.txt с данными о пользователях вида:
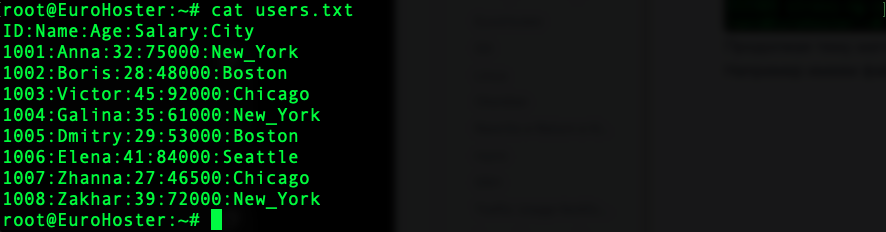
Можем посчитать среднюю заработную плату пользователя с помощью AWK:
awk -F ':' '{ sum+=$4 } END { print "Avg. salary:", sum/(NR-1) }' users.txt- -F - задаёт разделитель;
- sum+=$4 - добавляет значение 4-ого поля к переменной;
- print "Avg. salary:", sum/(NR-1) - рассчитывает среднее значение и выводит его.

С помощью выражений AWK можно заменить некоторые базовые утилиты, например head:
awk 'NR <= 5' users.txtКоманда выводит 5 первых строк файла users.txt.
Немного усложним выражение и выведем строки с третьей по пятую:
awk 'NR >= 3 && NR <= 5' users.txt- NR - номер текущей записи.

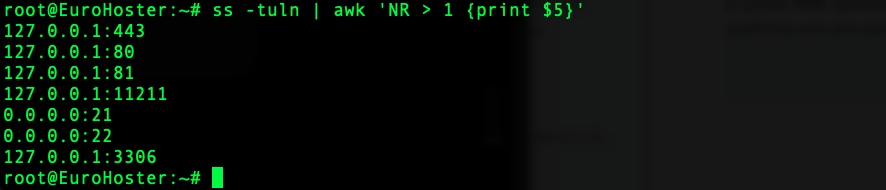
В целом AWK удобно использовать чтобы привести вывод команды в нужный нам вид, для удобства или для дальнейшей передачи. Соберём список открытых на сервере портов:
ss -tuln | awk 'NR > 1 {print $5}'- NR > 1 - начинает вывод со второй записи (первая запись в данном случае это название столбца).